I work with a lot of sites that are multi-homed or have a backup connection that, even though its backup still needs to be used at the same time for load balancing. Recently I was able to have a site that had a very slow MPLS link that was being moved to only backup – and a new SD-WAN link has been installed as primary. The MPLS link will go away after were sure the SD-WAN option works well.
The only time we want this link to become active is if SD-WAN fails. My first thought is no problem, just use a routing protocol and a static route – the routing protocol will be our preferred method, and we can just raise the admin distance of the default route to make it a backup. One problem in this scenario, the MPLS uses dynamic routing (EIGRP), and many other locations still use the MPLS for primary, or secondary connections, so we cannot even have this link up (admin state) or the MPLS will advertise the network.
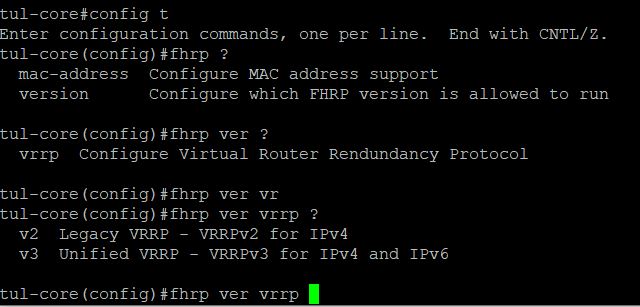
So, to recap what I need is a preferred route to our SD-WAN, and if SD-WAN fails, bring up the backup connection admin state and move traffic to it. Then of course, auto fix everything if SD-WAN comes back online. No problem! Cisco’s Event Manager to the rescue. Cisco’s Embedded Event Manager (EEM) (Copied From Cisco) –is a distributed and customized approach to event detection and recovery offered directly in a Cisco IOS device. EEM offers the ability to monitor events and take informational, corrective, or any desired EEM action when the monitored events occur or when a threshold is reached. An EEM policy is an entity that defines an event and the actions to be taken when that event occurs. When creating EEM scripts, you have two options TCL or CLI – in this case I am using just CLI.
Using EEM on the 3850 core I was able to detect if the default route learned VIA OSPF was removed from the routing table – if that happened, then run the command “No shut” on my MPLS uplink and EIGRP would take over. If the default route was learned at some point through OSPF when things were corrected – then run the command “Shut” on my MPLS uplink. This worked extremely well in combination with Link detection on the Fortigate, and OSPF default route distribution.
The Fortigate is my SD-WAN device, and my default gateway for the network. I am using link detection to test HTTP access to google. If my WAN interface cannot get a response from google.com in my set time (5 attempts, with 5 seconds between each attempt) then it will remove the default route from my routing table. When this happens the route will be removed from redistribution in OSPF, and removed from the Cisco core. EEM sees this event, and does my list of commands. Below shows the layout, and code to get this going. Interface 0/24 is my MPLS uplink.

First I made sure that the MPLS interface was shutdown and OSPF was up, and I was receiving the redistributed default route from the Fortigate.
config t
event manager applet MPLS-UP
event routing network 0.0.0.0/0 type remove protocol OSPF
action 1 cli command “enable”
action 2 cli command “config t”
action 3 cli command “int gig 1/0/24”
action 4 cli command “no shut”
action 5 cli command “exit”
event manager applet MPLS-DOWN
event routing network 0.0.0.0/0 type add protocol OSPF
action 1 cli command “enable”
action 2 cli command “config t”
action 3 cli command “int gig 1/0/24”
action 4 cli command “shut”
action 5 cli command “exit”
You can check status and history of events by using the show event manager commands.
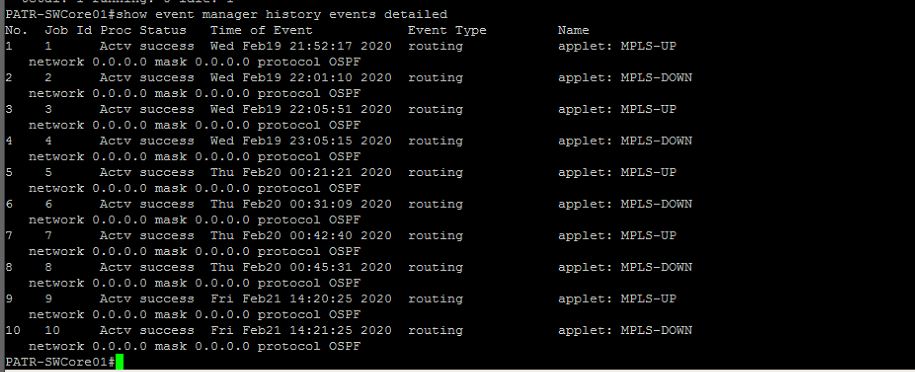
During a failure of my ISP, everything worked great. The default route was removed from OSPF, which caused an event that EEM matched – then it enabled the MPLS interface, and all routes/default was learned VIA EIGRP and the MPLS. When internet was restored, the MPLS interface was shutdown, and all traffic started flowing over SD-WAN.