When deploying wireless networks one of the best practices is to limit the SSIDs used within the WLAN. The reason we want to limit the amount of SSIDs, is the SSID announcement is sent through a Beacon frame. This frame is a broadcast to all stations. This happens every 100 MS or 102.4 MS according to how busy the medium is. In all documentation and great blogs I have not found a lot of visual examples of what actually happens, So I thought this might be a cool blog entry to write.
On top of the constant beacon broadcasting of the APs, when a client wants to join, it will send a probe request to the broadcast address of ff:ff:ff:ff:ff:ff and all APs will respond with a probe response frame directly to the station informing the client of the SSID and its supported capabilities. Beacons and probe request/response frames are the reason we need to limit the amount of SSIDs. For instance (and I will show this below) if you had 1 AP with 5 SSIDs, with 1 client trying to connect, the AP would be sending somewhere around 50 Beacons in 1 seconds, and 5 probe responses. This is might not seem like a lot of air time used at first, but think if you had 5 clients trying to connect at the same time, or maybe 2 or more APs on the same channel, with 5 clients trying to connect at the same time. Then the airtime usage goes up huge. Since wireless is half-duplex this takes increases the time it takes for clients to do what they need to do on the spectrum.
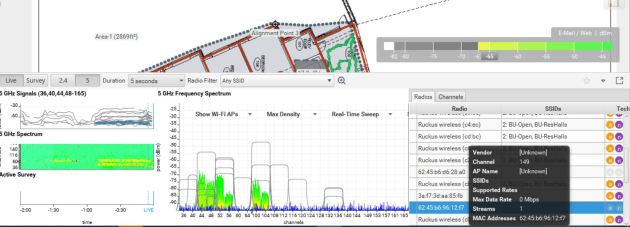
To show the results, I am using the Ekahua sidekick with spectrum analysis. I will start with 1 AP broadcasting 1 ssid, and then add another AP on the same channel. From there I will increase the SSIDs and show the airtime usage. I hope to show why it is important to keep SSID overhead to a minimum. The gear used will be a Ruckus Zondirector, Ruckus 7982, and R710 APs. I am lucky enough to have an area with very little neighboring wifi networks, so I am testing with 1 wireless client in range of the AP to limit, and show the probe request/response traffic. I am broadcasting the test SSIDs on channel 11 and channel 157.
First lets look at just 1 AP with one SSID broadcasting.
As you can see from above, very little spectrum usage. Again, no clients are connected to an SSID, and only one device would be doing probe requests.
I did a packet capture next, check out the analysis data and the size of the capture. I only let the capture run for 1 minute (60 seconds). The size of the file was roughly 165 Kb. The red in the graph below represents beacon frames, and the dots/green are probe requests vs probe responses.
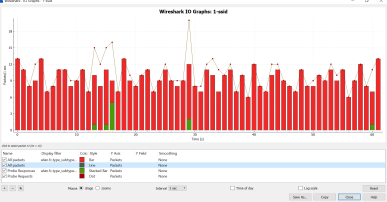
I then added the other AP on the exact same channels, still only broadcasting 1 SSID. Spectrum usage definitely increased but only by very little. Below are the spectrum density graphs and Wireshark IO graph.
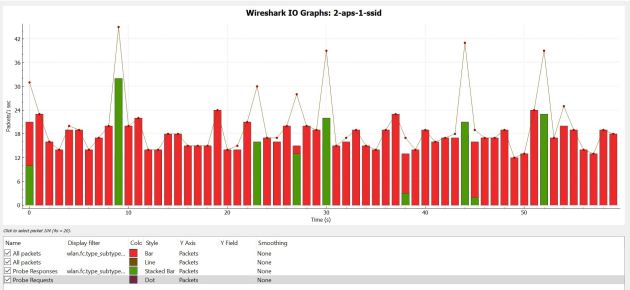
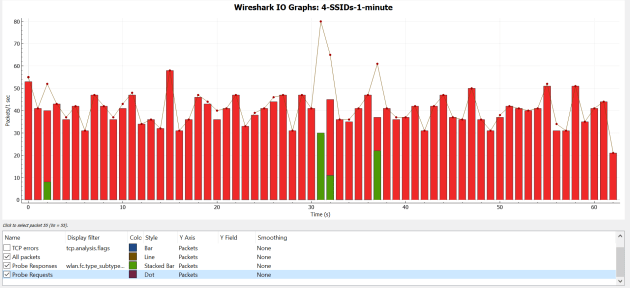
Now, lets increase things a bit – I will start broadcasting 4 SSIDs from 1 AP.
Spectrum usage from 1 AP broadcasting 4 SSIDs:
Below is 2 APs broadcasting 4 SSIDs – all on the same channels.
When comparing the wireshark IO graph we can really see how many Beacon frames are sent and compare those between 1 and 2 APs. Another cool thing to note is the size of the wireless PCAPs – each running for 1 minute, the 1 AP broadcasting 4 SSIDs size was 662 KB, and 2 APs broadcasting 4 SSIDs each was just about double at 1200 KB. In the graphs below, red indicates the number of Beacon frames.
2 APs – 4 SSIDs:
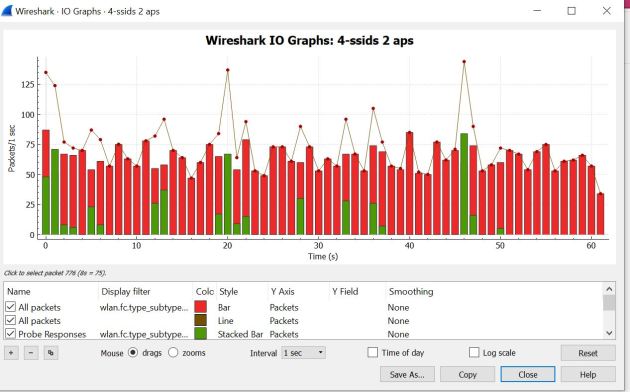
After all the testing, we have a big increase from just adding 1 SSID and an even bigger increase from having another AP broadcasting on the same channels. This isn’t ground breaking but cool to see in action. I have seen many many clients have at least 6 SSIDs broadcasting, and this give some good illustration on why we need to reduce the amount of SSIDs in use. There are a few tools out to calculate the SSID overhead – tools such as http://www.revolutionwifi.net.
Check out the below picture comparing 1 SSID to 4 SSIDs just from 1 AP for 2.4 and 5 gig.

1AP 1-SSID

1 AP 4-SSIDs
")
1 AP 1 SSID

1 AP 4 SSIDs
.


")