Posted by on July 7, 2020
This entry details how to create a static route in both the GUI and CLI of the Fortigate firewall. Specifically I am using FortiOS 6.2.4 but its pretty much been the same for years.
Lets start by talking through the things that will be needed to create the static route.
– Subnet – this is what we want to route to, for a default route its 0.0.0.0/0 but if we wanted a more specific route, lets say to 192.168.100.0/24.
– Destination Interface – Next hop interface we want to send traffic out of.
– Gateway address – Directly connected interface neighbor that we want the next hop for 192.168.100.0/24 to be.
– Administrative Distance– is a feature used by routers to select the best path to a destination when multiple paths to the same destination are present. Lowest AD wins and will be placed in the routing table.
Advanced option – Priority – To build on AD definition – What if two routes exist in the routing table to the same destination with the same AD? This is where Priority comes in. Lowest priority wins. By selecting a priority you can have multiple routes to the same destination in the routing table, but one would be preferred over the other. This comes in very hand for Reverse Path forwarding issues.
So after all that’s said, we need to route 192.168.100.0/24 to our LAN interface with a next hop of 192.168.1.2.
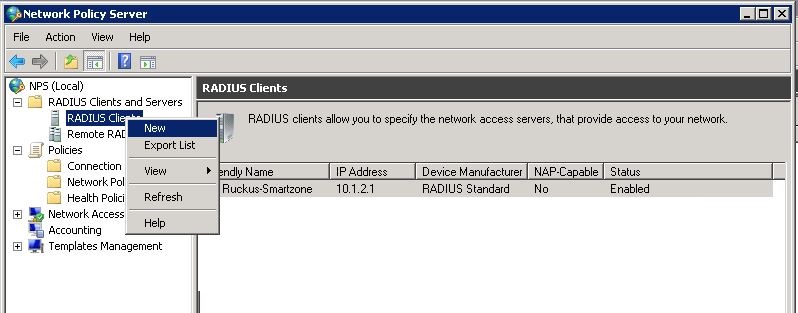
First lets create this in the GUI. Navigate to network – static routes – and create a new one.
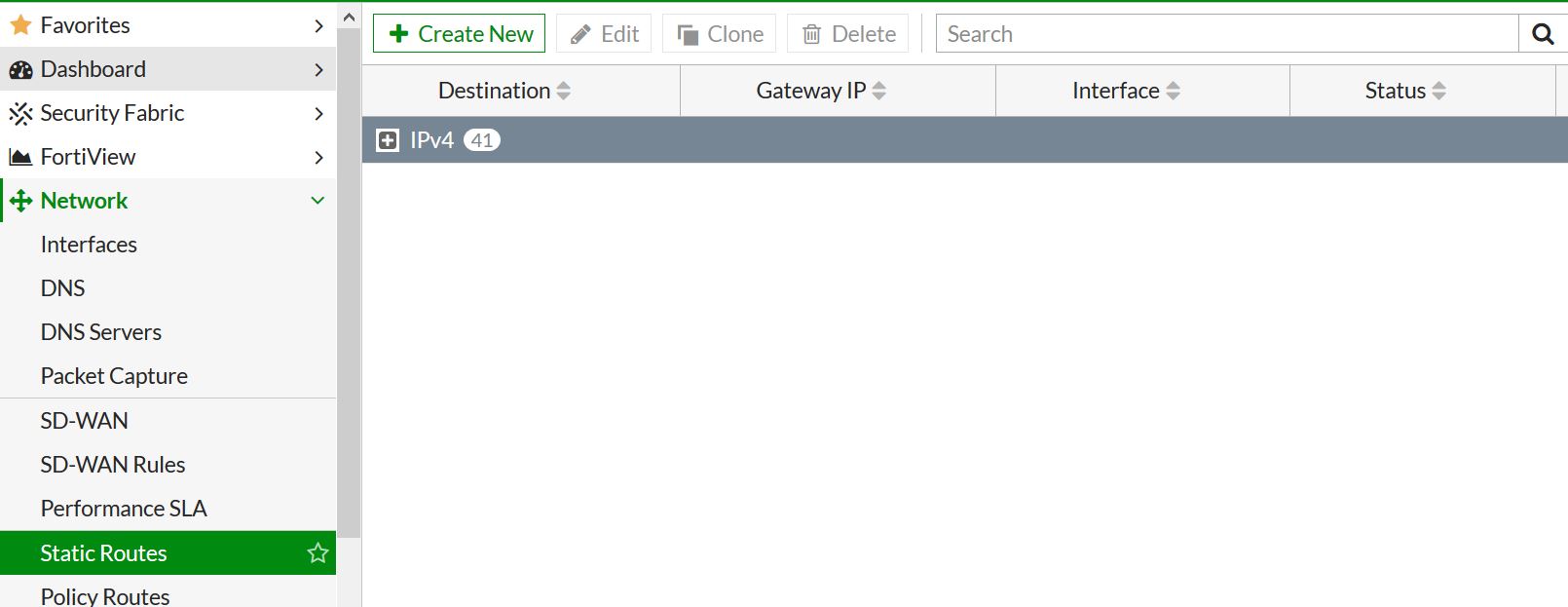 .
.
Now we will just insert the needed info. I am leaving the AD at 10 – which is default.
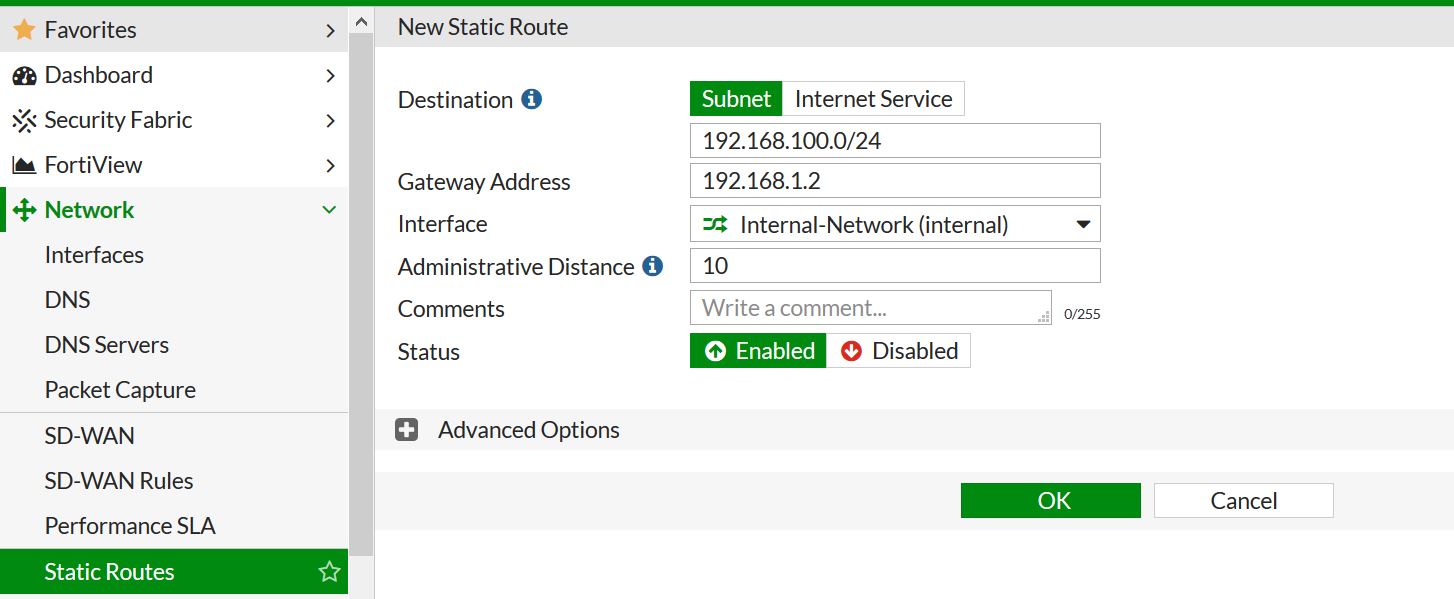
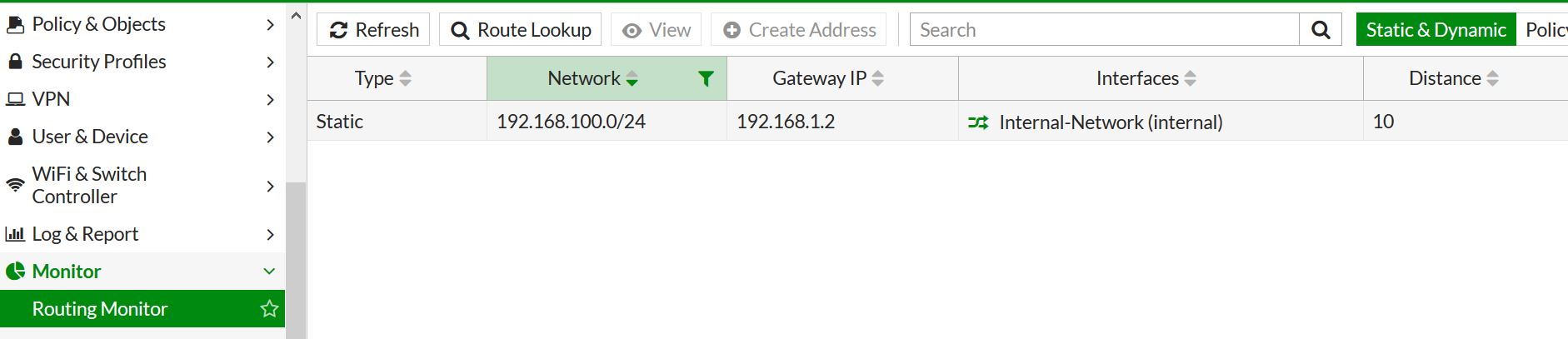
Press OK – and Bam! route created. We can check that the route has been created and is the routing table by going to monitor – routing monitor.
Next lets do the same thing in CLI.
First route creation. When you create the route edit the next available sequence number. In this case its 46.
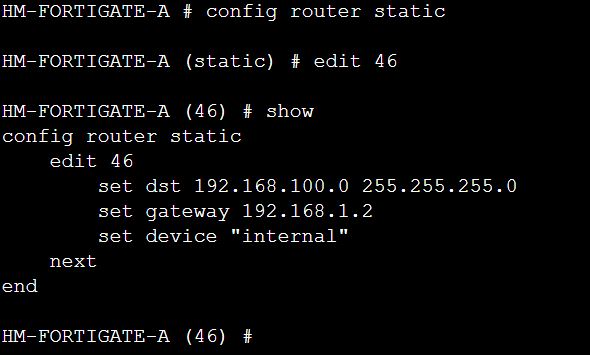
You can see if your route is in the routing table in CLI by running the command “get router info routing-table all” but in this case I am using the static option, and grepping just what I need to see.